实验要求
-
了解进程与线程的概念、相关结构和实现。
-
实现内核线程的创建、调度、切换。(栈分配、上下文切换)
-
了解缺页异常的处理过程,实现进程的栈增长。
实验过程
进程模型设计
这一部分主要是对本次实验的进程设计的知识普及,但是辐射几乎全部的后续实验内容,这里只列出与后续实验(或者一些实验没提及但是需要实现的功能)对应的表格。
进程模型设计 相关实验内容
进程控制块 PID
进程上下文 进程调度的实现, 缺页异常的处理
进程页表 进程管理器的初始化
进程调度 进程调度的实现 进程的内存布局 进程管理器的初始化, 内核线程的创建, 缺页异常的处理 ---------------- ------------------------------------------------------
进程管理器的初始化
首先是确定KSTACK_DEF_PAGE的值,这其实在上面有提及过,即512,这是因为我们默认的内核栈大小为
512 个 4KiB 的页面,即 2MiB。(远小于 4GiB
的栈空间,这一部分与后面的缺页处理相关)
接着按照以下步骤完成init函数:
-
设置内核相关信息
-
创建内核结构体
-
内核进程的初始化状态
这里包括manager::init()的实现。
进程调度的实现
移除了上一次实验的计时器模块等(在clock中),然后在 TSS
中(gdt中)声明一块新的中断处理栈,并将它加载到时钟中断的 IDT
中(register_idt)。
接着使用已经定义好的 as_handler
宏(使用汇编代码来手动保存和恢复寄存器)重新定义中断处理函数。
在上面的中断处理函数中调用了 crate::proc::switch
函数,它也是需要我们实现的一部分,其中使用的save_current 和
switch_next 函数也一样,这一部分主要参照以下流程进行实现:
-
关闭中断
-
保存当前进程的上下文
-
更新当前进程的状态
-
将当前进程放入就绪队列
-
从就绪队列中选取下一个进程
-
切换进程上下文和页表
值得一提的是对Dead和Blocked状态的处理,这一部分的实现并未使得结果出现错误,但是我暂时还不能保证实现的完全正确。在switch_next函数中我使用了while循环来遍历队列,这里没有进行其他的处理,所以经常性的有错误正是陷入了无限的循环,即队列里有元素且状态都不是Ready,因为我默认了这一错误的发生是因为我的实现错误,事实上我也确实遇到了无限循环的情况,所以我没有进行额外的处理。
还有ProcessId的新建,我使用原子操作保证每一次 ProcessId::new()
调用都会返回一个不同的 ProcessId 。
进程信息的获取
环境变量
src/proc/mod.rs 中的 env
函数,我采用先实现ProcessInner中的env函数去调用proc_data的env函数,然后再调用实现的env函数的方式。
进程返回值
先为 ProcessManager 添加相关的处理函数,使得外部函数可以获取指定进程的exit code,然后再在wait中进行使用。
内核线程的创建
参照我们的内存布局预设,我们需要为每个线程分配一个初始栈,根据
pid我们可以算出栈的起始位置和初始栈顶位置,再使用elf::map_range
函数来进行新的页面的映射。这一部分是在alloc_init_stack实现。
接着是用于测试的spawn_kernel_thread的实现。除了调用上面的函数进行栈的分配,还需要利用
ProcessContext 的 init_stack_frame
函数它们放入初始化的进程栈帧中,然后将线程放入进程管理器和就绪队列中。
缺页异常的处理
本次实验的缺页异常的处理主要是为栈空间进行自动扩容。
首先,在 src/interrupt/exception.rs
中,重新定义缺页异常的处理函数,从CR2寄存器获得尝试访问的地址,同时获取缺页异常的错误码。
接着完善缺页异常的相关处理函数:ProcessManager的handle_page_fault函数,利用上面获取的值进行栈的重新分配,如果缺页异常的地址不在当前进程的栈空间中或者是由非预期异常导致的则返回false。
这个函数还调用了一个我实现的ProcessInner的expand_stack函数,这个函数的实现是根据栈的大小进行新的页面的映射。
进程的退出
因为目前我们没有实现系统调用,内核线程的退出是它主动调用内核的
process_exit 来实现的。
这之中由我实现的是ProcessInner的kill函数。其完成的工作是在进程退出时,记录exit_code,将进程的状态设置为
Dead,并删除进程运行时需要的部分数据。(这里只简陋地直接地删除ProcessData)
关键代码
proc/mod.rs:
pub fn init() {
let mut kproc_data = ProcessData::new();
kproc_data.set_stack(VirtAddr::new(KSTACK_INIT_BOT), KSTACK_DEF_SIZE);
trace!("Init process data: {:#?}", kproc_data);
// kernel process
let kproc = Process::new(
/* process name */ "kernel".into(),
/* parent process */ None,
/* page table */ PageTableContext::new(),
/* process data */ Some(kproc_data),
);//{ /* FIXME: create kernel process */ };
manager::init(kproc);
info!("Process Manager Initialized.");
}
pub fn switch(context: &mut ProcessContext) {
x86_64::instructions::interrupts::without_interrupts(|| {
let process_manager = get_process_manager();
process_manager.save_current(context);
let pro = process_manager.current();
let current_pid = pro.pid();
let mut pro = pro.write();
if pro.status() != ProgramStatus::Dead && pro.status() != ProgramStatus::Blocked {
process_manager.push_ready(current_pid);
pro.pause();
pro.tick();
}
drop(pro);
let next_pid = process_manager.switch_next(context);
// trace!("Switched to process {}", next_pid);
});
}
pub fn env(key: &str) -> Option<String> {
x86_64::instructions::interrupts::without_interrupts(|| {
// get current process's environment variable
get_process_manager().current().read().env(key)
})
}
process.rs:
impl Process {
pub fn alloc_init_stack(&self) -> VirtAddr {
// alloc init stack base on self pid
// Calculate the stack start address based on the PID
let pid: u64 = self.pid.into();
let stack_start = STACK_MAX - pid * STACK_MAX_SIZE;
let stack_start = VirtAddr::new(stack_start);
// Get the frame allocator
// let mut frame_allocator = get_frame_alloc_for_sure();
let frame_allocator = &mut *get_frame_alloc_for_sure();
// Get the page table of the process
let page_table = &mut self.read().page_table.as_ref().unwrap().mapper();
// Map the memory for the stack
let stack_size_in_pages = STACK_DEF_PAGE;
map_range(stack_start.as_u64(), stack_size_in_pages, page_table, &mut *frame_allocator).expect("Failed to map stack");
// Return the stack top address
stack_start + STACK_DEF_SIZE - 8
}
}
impl ProcessInner {
pub fn env(&self, key: &str) -> Option<String> {
x86_64::instructions::interrupts::without_interrupts(|| {
self.proc_data.as_ref().unwrap().env(key)
})
}
/// Save the process's context
/// mark the process as ready
pub(super) fn save(&mut self, context: &ProcessContext) {
// save the process's context
self.context.save(context);
}
/// Restore the process's context
/// mark the process as running
pub(super) fn restore(&mut self, context: &mut ProcessContext) {
// restore the process's context
self.context.restore(context);
// restore the process's page table
self.page_table.as_ref().unwrap().load();
}
pub fn expand_stack(&mut self, fault_addr: VirtAddr, stack_start: VirtAddr) -> Result<(), ()> {
// Calculate the number of pages to allocate
let stack_start_addr = stack_start;
let num_pages = (stack_start_addr - fault_addr) / PAGE_SIZE + 1;
// Get the frame allocator and page table mapper
let frame_allocator = &mut *get_frame_alloc_for_sure();
let mapper = &mut self.page_table.as_ref().unwrap().mapper();
// Allocate the pages and update the page table
let stack_end_addr = stack_start_addr - num_pages * PAGE_SIZE;
map_range(stack_end_addr.as_u64(), num_pages, mapper, frame_allocator);
Ok(())
}
pub fn kill(&mut self, ret: isize) {
// set exit code
self.exit_code = Some(ret);
// set status to dead
self.status = ProgramStatus::Dead;
// take and drop unused resources
drop(self.proc_data.take());
self.proc_data = None;
}
}
manager.rs:
pub fn init(init: Arc<Process>) {
// set init process as Running
init.write().resume();
// set processor's current pid to init's pid
processor::set_pid(init.pid());
PROCESS_MANAGER.call_once(|| ProcessManager::new(init));
}
impl ProcessManager {
pub fn save_current(&self, context: &ProcessContext) {
// update current process's tick count
// save current process's context
let binding = self.current();
let mut proc = binding.write();
if proc.status() == ProgramStatus::Running {
proc.tick();
proc.save(context);
}
}
pub fn switch_next(&self, context: &mut ProcessContext) -> ProcessId {
let mut ready_queue = self.ready_queue.lock();
// fetch the next process from ready queue
while let Some(pid) = ready_queue.pop_front() {
// info!("!!!");
let proc = self.get_proc(&pid).unwrap();
let mut proc = proc.write();
// check if the next process is ready,
// continue to fetch if not ready
if proc.status() == ProgramStatus::Ready {
proc.resume();
// restore next process's context
proc.restore(context);
// update processor's current pid
processor::set_pid(pid);
drop(proc);
// return next process's pid
return pid;
} else {
ready_queue.push_back(pid);
drop(proc);
}
}
panic!("No process is ready to run.");
}
pub fn spawn_kernel_thread(
&self,
entry: VirtAddr,
name: String,
proc_data: Option<ProcessData>,
) -> ProcessId {
let kproc = self.get_proc(&KERNEL_PID).unwrap();
let page_table = kproc.read().clone_page_table();
let proc = Process::new(name, Some(Arc::downgrade(&kproc)), page_table, proc_data);
// alloc stack for the new process base on pid
let stack_top = proc.alloc_init_stack();
// set the stack frame
{
let mut proc_write = proc.write();
// proc_write.set_proc_data_stack(stack_top, STACK_MAX_SIZE);
proc_write.init_context(entry, stack_top);
}
// add to process map
let pid = proc.pid();
self.processes.write().insert(pid, proc);
// push to ready queue
let mut ready_queue = self.ready_queue.lock();
ready_queue.push_back(pid);
// return new process pid
pid
}
pub fn handle_page_fault(&self, addr: VirtAddr, err_code: PageFaultErrorCode) -> bool {
// handle page fault
let current_process = self.current();
let pid: u64 = current_process.pid().into();
let stack_start = STACK_MAX - pid * STACK_MAX_SIZE;
let stack_start = VirtAddr::new(stack_start);
let mut inner = current_process.write();
if err_code.contains(PageFaultErrorCode::PROTECTION_VIOLATION) {
// error!("Protection violation at {:#x}", addr);
return false;
}
// Check if the page fault is caused by stack overflow
if addr < stack_start {
// Try to expand the stack
if let Err(_) = inner.expand_stack(addr, stack_start) {
return false;
}
} else {
// The page fault is not caused by stack overflow
return false;
}
true
}
pub fn exit_status(&self, pid: ProcessId) -> Option<isize> {
self.get_proc(&pid).and_then(|proc| proc.read().exit_code())
}
}
clock.rs:
pub unsafe fn register_idt(idt: &mut InterruptDescriptorTable) {
idt[Interrupts::IrqBase as u8 + Irq::Timer as u8]
.set_handler_fn(clock_handler)
.set_stack_index(gdt::CLOCK_IST_INDEX);
}
pub extern "C" fn clock(mut context: ProcessContext) {
x86_64::instructions::interrupts::without_interrupts(|| {
switch(&mut context);
super::ack();
})
}
as_handler!(clock);
pid.rs:
impl ProcessId {
pub fn new() -> Self {
// FIXME: Get a unique PID
let pid = PID_COUNTER.fetch_add(1, Ordering::SeqCst);
Self(pid)
}
}
exceptions.rs:
pub extern "x86-interrupt" fn page_fault_handler(
stack_frame: InterruptStackFrame,
err_code: PageFaultErrorCode,
) {
if !crate::proc::handle_page_fault(Cr2::read().expect("Failed to read CR2"), err_code) {
warn!(
"EXCEPTION: PAGE FAULT, ERROR_CODE: {:?}\n\nTrying to access: {:#x}\n{:#?}",
err_code,
Cr2::read().expect("Failed to read CR2"),
stack_frame
);
// print info about which process causes page fault ?
panic!("Cannot handle page fault!");
}
}
utils/mod.rs:
pub fn new_stack_test_thread() {
let pid = spawn_kernel_thread(
func::stack_test,
alloc::string::String::from("stack"),
None,
);
// wait for progress exit
wait(pid);
}
fn wait(pid: ProcessId) {
loop {
// try to get the status of the process
let status = get_process_manager().exit_status(pid);
// HINT: it's better to use the exit code
if let None = status/* is the process exited? */ {
x86_64::instructions::hlt();
} else {
break;
}
}
}
data.rs:
impl ProcessData {
pub fn is_on_stack(&self, addr: VirtAddr) -> bool {
if let Some(stack_segment) = self.stack_segment {
let start = stack_segment.start.start_address();
let end = stack_segment.end.start_address();
addr >= start && addr < end
} else {
false
}
}
}
gdt.rs:
pub const CLOCK_IST_INDEX: u16 = 2;
pub const IST_SIZES: [usize; 4] = [0x1000, 0x1000, 0x1000, 0x1000];
lazy_static! {
static ref TSS: TaskStateSegment = {
let mut tss = TaskStateSegment::new();
/*...*/
tss.interrupt_stack_table[CLOCK_IST_INDEX as usize] = {
const STACK_SIZE: usize = IST_SIZES[3];
static mut STACK: [u8; STACK_SIZE] = [0; STACK_SIZE];
let stack_start = VirtAddr::from_ptr(unsafe { STACK.as_ptr() });
let stack_end = stack_start + STACK_SIZE as u64;
info!(
"CLOCK Stack: 0x{:016x}-0x{:016x}",
stack_start.as_u64(),
stack_end.as_u64()
);
stack_end
};
tss
};
}
实验结果
阶段成果一:
在成功实现进程调度后,你应当可以观察到内核进程不断被调度,并继续执行的情况。
阶段成果二: 在成功实现内核线程的创建后,尝试在 kernel_main 中使用
test 命令来创建多个内核线程,它们应当被并发地调度执行。
:::: box
::: {.columns-flow count=”2”}
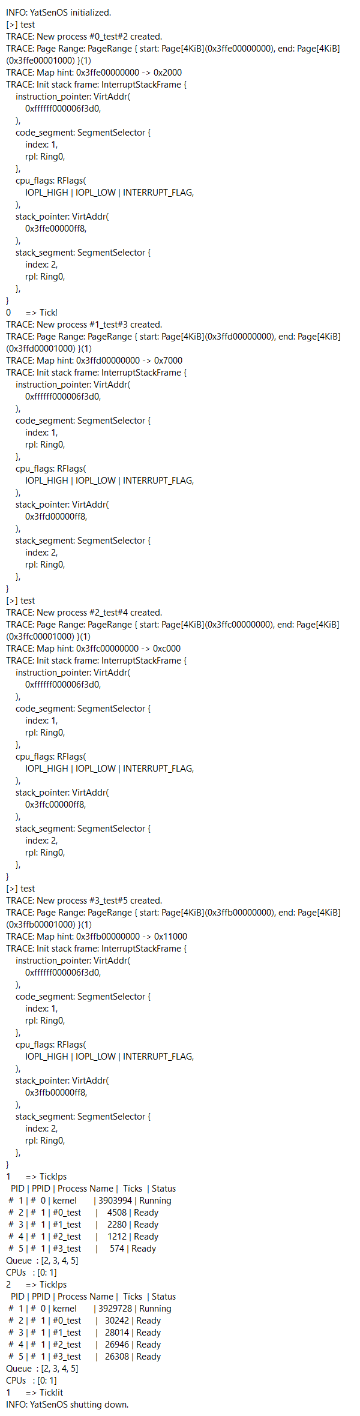
- 它们是否按照预期的顺序保存和恢复执行?
是的,tick前的数字按0到3的顺序循环。
- 有没有进程插队、执行状态不正确、执行时间不平均的情况?
没有。
- 它们使用的栈是否符合预期?
#0_test#2
Init stack frame: InterruptStackFrame {
stack_pointer: VirtAddr(
0x3ffe00000ff8,
),
}
#1_test#3
Init stack frame: InterruptStackFrame {
stack_pointer: VirtAddr(
0x3ffd00000ff8,
),
}
#2_test#4
Init stack frame: InterruptStackFrame {
stack_pointer: VirtAddr(
0x3ffc00000ff8,
),
}
#3_test#5
Init stack frame: InterruptStackFrame {
stack_pointer: VirtAddr(
0x3ffb00000ff8,
),
}
这是符合预期的。
- 是否有进程存在声明退出后继续执行的情况?
否,exit完后就结束了。
- 就绪队列中是否存在重复的进程?
否,始终是[2,3,4,5]。
:::
::::
阶段性成果三: 在成功实现缺页异常的处理后,尝试在 kernel_main 中使用
stack
命令来创建一个栈使用很大的内核线程,而它应当被正确地处理,不会导致进程的崩溃。
同时,此命令应该能够等待这一进程结束运行后,再进行下一步的操作。
:::: box
::: {.columns-flow count=”2”}
 如图所示,stack触发了缺页异常并进行了正确地处理,没有导致进程崩溃,同时这一进程结束运行后仍能进行下一步操作。
:::
::::
如图所示,stack触发了缺页异常并进行了正确地处理,没有导致进程崩溃,同时这一进程结束运行后仍能进行下一步操作。
:::
::::
实验总结
在这个实验中,我探索了操作系统中进程管理和调度的核心概念。我首先理解了进程的基本构成,包括进程控制块(PCB)和进程上下文。我了解到,PCB是操作系统用于管理进程的关键数据结构,而进程上下文则保存了进程运行所必需的状态信息。
我学习了如何通过页表来管理进程的地址空间,理解了在进程切换时,如何通过更新Cr3寄存器来切换页表,从而实现进程地址空间的切换。
此外,我还探讨了在处理缺页异常和时钟中断时,为什么需要切换栈。我了解到,这是为了保护正在运行的程序的状态,避免中断处理程序覆盖重要的数据。
总的来说,这个实验加深了我对操作系统进程管理和调度的理解,也让我了解了操作系统设计和实现的一些关键技术。
思考题&加分项
为什么在初始化进程管理器时需要将它置为正在运行的状态?能否通过将它置为就绪状态并放入就绪队列来实现?这样的实现可能会遇到什么问题?
进程管理器是操作系统中的一个关键组件,负责管理系统中的进程(即正在执行的程序)。将进程管理器置为正在运行的状态可以确保它能够立即开始对系统中的进程进行管理和调度。 如果将进程管理器置为就绪状态并放入就绪队列可能遇到的问题:
-
优先级问题:如果进程管理器被放入就绪队列,那么它的优先级将影响它何时被调度执行。在某些情况下,进程管理器可能需要具有最高的优先级,以确保系统中其他进程的正常管理和调度。
-
竞争条件:如果进程管理器被放入就绪队列,那么在系统启动期间,可能会出现对其状态的竞争条件。这可能导致系统启动过程中的不确定行为,甚至导致系统无法正确初始化和启动。
因此,将进程管理器置为正在运行的状态是为了确保系统在启动时能够立即进行进程管理,并避免潜在的竞争条件和优先级问题。
在 src/proc/process.rs 中,有两次实现 Deref 和一次实现 DerefMut 的代码,它们分别是为了什么?使用这种方式提供了什么便利?
首先,Process类型实现了Deref,它的目标类型是Arc<RwLock<ProcessInner>>。这意味着,可以通过Process类型的实例直接访问ProcessInner的方法和字段,而无需先获取内部的Arc<RwLock<ProcessInner>>。
接下来,ProcessInner类型实现了Deref和DerefMut,它们的目标类型是ProcessData。这使得可以直接通过ProcessInner的实例访问ProcessData的方法和字段。这样就可以更方便地访问ProcessData,而不需要每次都通过proc_data字段。
这种方式的优势在于提供了一种简洁的语法来访问内部数据。使得我们可以像操作直接包含的字段一样操作这些内部数据,而无需显式的解引用操作或访问内部的字段。这使得你的代码更加直观,也更易于阅读和维护。同时,DerefMut的实现也允许你在必要时修改这些内部数据。
中断的处理过程默认是不切换栈的,即在中断发生前的栈上继续处理中断过程,为什么在处理缺页异常和时钟中断时需要切换栈?如果不为它们切换栈会分别带来哪些问题?请假设具体的场景、或通过实际尝试进行回答。
在处理中断时切换栈是因为我们不希望中断处理例程可能会覆盖正在运行的程序的堆栈。特别是在处理缺页异常和时钟中断时,这些中断可能会在任何时间发生,因此在处理它们时我们需要特别小心,避免覆盖正在运行的程序的堆栈。
如果不为它们切换栈,可能会导致以下问题:
-
缺页异常:如果处理缺页异常的代码过大或者复杂,可能会使用大量的栈空间。如果我们在原来的栈上运行这些代码,可能会覆盖掉栈上的其他重要数据,导致程序崩溃。
-
时钟中断:时钟中断可以在任何时刻发生,如果我们在原来的栈上处理时钟中断,可能会打乱程序的执行流程,导致程序状态混乱。
总的来说,切换栈是为了保护程序的状态,避免中断处理程序覆盖掉重要的数据。